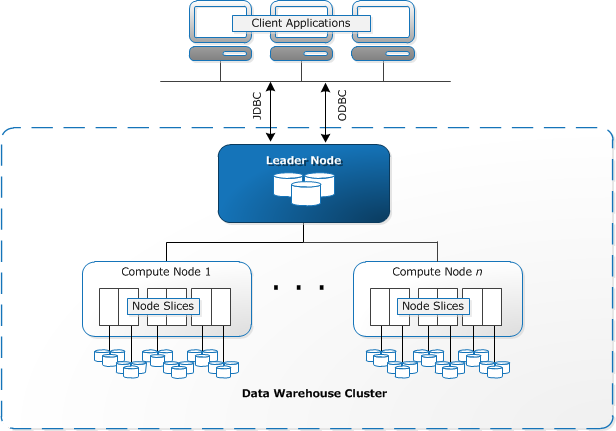
Redshift is an collection of compute resources which we call nodes
A group of nodes is called a cluster
Each cluster runs AWS Redshift engine and each cluster has 1 or more DBs
Each cluster has Leader Node and Compute Nodes
Leader Node receives the query from client applications and creates an query plan
The query plan is then executed by the compute nodes and the final result is aggregated by the leader node which sends the final result to the clients
The compute nodes can transfer data between themselves
Compute Nodes are further divided into Node slices. Slice is an logical partition for disk storage
Each slice consist of this own set of data
The clients communicate with Redshift using JDBC/ OBDC drivers
NOTE
- The Leader node of Redshift is designed based on PostgreSQL
- So the same way we communicate with PostgreSQL we can communicate with Redshift
Data Warehouse System Architecture - Amazon Redshift
Amazon Redshift Architecture | Towards Data Science
Node Types
Leader Node
SQL endpoint
Stores metadata
Coordinates parallel SQL processing
Compute Node
Local, Columnar Storage
Execute query in parallel
Load, Backup, Restore
Node Configurations
Dense Storage (DS2, RA3) - HDD
Dense Compute (DC2) - SDD