It is a serverless ETL tool
Extract data from different source systems, transform the data for analysis and load the data into Data Warehouse
It is built as an replacement to Hadoop
It was specifically designed to process large datasets
Glue uses Spark as its backend for processing the job
The supported languages for writing code in glue: Python and Scala
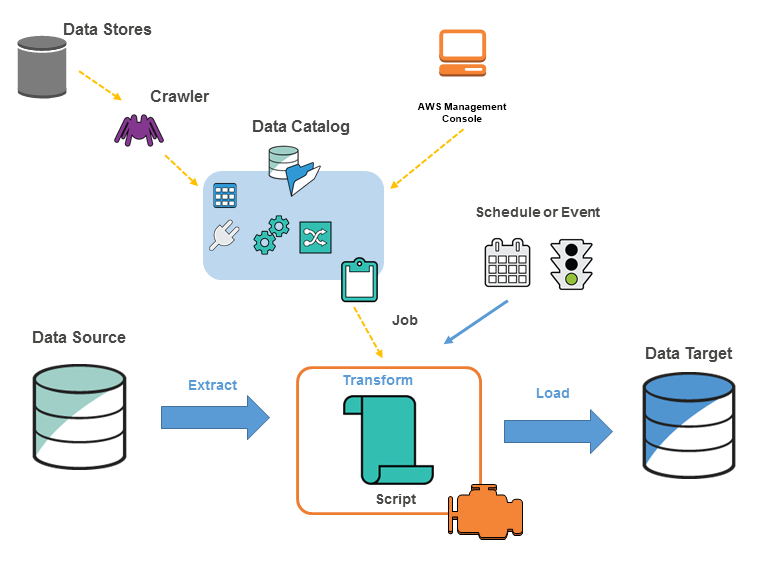
Glue Data Catalog
Persistent metadata store in Glue
Table definition, job definition, etc. are stored here. It is similar to the Hive metastore
Each AWS account has one catalog per region
Classifier
It is used to infer schema to the data
If we do not specify an classifier build in default classifier is used
Connection
Consist of the properties that are required to connect to the data stores
Crawler
A program that connects to a metastore
It uses the list of classifier to provide an schema to the data
Data Store
Location for persistently storing data
E.g. S3, DynamoDB