Partitioning
It is the technique to physically divide your data into separate data stores to improve scalability, reduce contention and optimize performance
Benefits of Partitioning
- Improved Scalability: Each partition can be saved on a node on a different server
- Improved Performance: Operations that effect more than one partition can run in parallel
- Improved Security: We can split the data based on the security requirement
- Match the data store to pattern of use : Use different types of data stores to store the data based on its usage
- Improved Availability: As data is distributed we can avoid a single point of failure
Designing Partitions
- Avoid Cross Partition Joins. The queries should be as self-contained as possible
- Data lookup is an expensive operation so replicate static data that is referenced frequently
- Periodic Rebalancing of Shards should be performed as some partitions might become hot spots causing performance degradation
- Avoid accessing data from multiple partitions on a frequent bases. If this is the case store them all in a single partition
Types of Partitioning
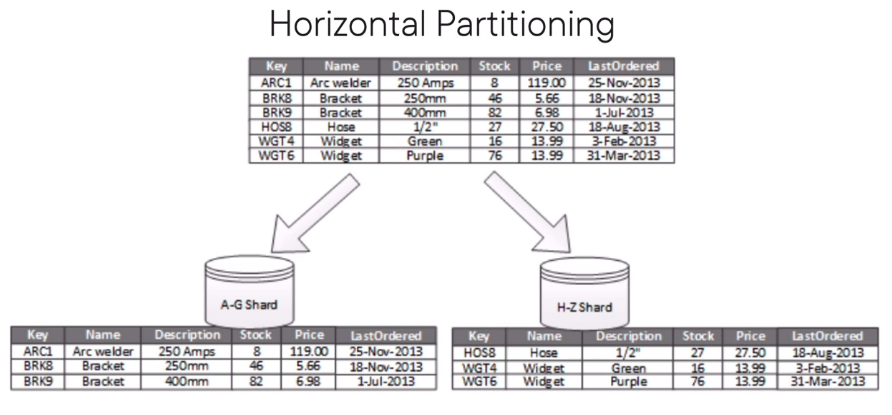
Horizontal Partitioning (Sharding)
Splitting the data based on values. e.g. Partition by date
Each partition is stored in a different data store/ node but they all have the same schema
Each partition holds a specific subset of the whole data
Selecting the correct partitioning key in this type of approach is very vital (The data should be distributed as evenly as possible).
If suboptimal columns are used the performance of the data store can be effected drastically.
It is difficult to change the partition key once data has been loaded into the system
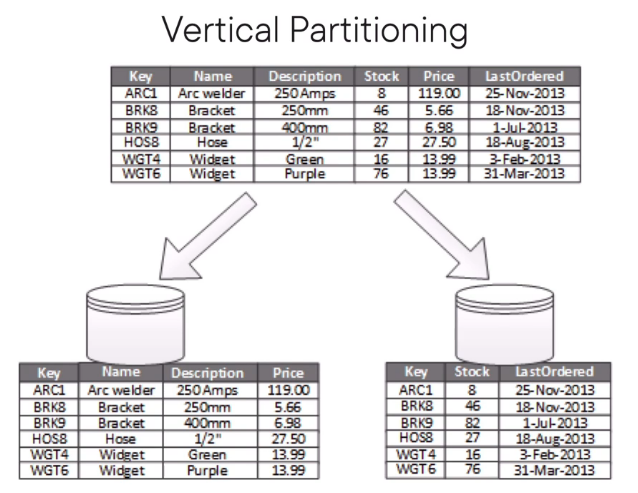
Vertical Partitioning
Each partition holds a subset of fields that are stored in the data store (Splitting data based on columns)
The goal of this type of partitioning is to reduce the performance cost associated with I/O
The data that is stored in one partition will be accessed more frequently compared to others
This approach allows to apply different security constraints on different data. PII data can be stored in a separate partition where strict security constraints can be used
Allows to save slowly changing data and fast changing data separately
Functional Partitioning
Separate data from different domains into different physical nodes to ensure better isolation and performance
It allows to avoid concurrent access to the same table
Criteria for choosing Partition Key
High Cardinality
If the key only stores a few values. e.g. Yes/ No, Male/ Female, etc. the system will not scale horizontally
Partition Reshuffling
The column selected for partitioning should not be such that it uses items to be redistributed frequently
Generates contention as two partitions cannot be accessed as insert operation is taking place
Older partitions will have less frequency
Frequency
The column used for partitioning should have elements that have an even frequency distribution i.e. all partitions will have equal number of entries
A partition that is frequently accessed/ overloaded with data is referred to as a hot partition